This article was written after finishing my first Kaggle challenge - TalkingData AdTracking Fraud Detection Challenge to share what I've learnt from this challenge. In this article, I'll begin with a breif introduction to Kaggle and to TalkingData AdTracking Fraud Detection Challenge, then I will talk about what I've learnt after this challenge.
Kaggle Platform

According to Wikipedia,
Kaggle is a platform for predictive modelling and analytics competitions in which statisticians and data miners compete to produce the best models for predicting and describing the datasets uploaded by companies and users. This crowdsourcing approach relies on the fact that there are countless strategies that can be applied to any predictive modelling task and it is impossible to know beforehand which technique or analyst will be most effective.
Recently, people added more functionalities to Kaggle, such as sharing your code in "Kernels", asking a question in "Discussions", learning a new Data Science technique in "Learn" and finding your job in "Jobs" etc. Kaggle has became the # 1 platform for data scientists and machine learners.
TalkingData AdTracking Fraud Detection Challenge

Fraud risk is everywhere, but for companies that advertise online, click fraud can happen at an overwhelming volume, resulting in misleading click data and wasted money. Ad channels can drive up costs by simply clicking on the ad at a large scale. With over 1 billion smart mobile devices in active use every month, China is the largest mobile market in the world and therefore suffers from huge volumes of fradulent traffic.
TalkingData, China’s largest independent big data service platform, covers over 70% of active mobile devices nationwide. They handle 3 billion clicks per day, of which 90% are potentially fraudulent. Their current approach to prevent click fraud for app developers is to measure the journey of a user’s click across their portfolio, and flag IP addresses who produce lots of clicks, but never end up installing apps. With this information, they've built an IP blacklist and device blacklist.
While successful, they want to always be one step ahead of fraudsters and have turned to the Kaggle community for help in further developing their solution. In their 2nd competition with Kaggle, you’re challenged to build an algorithm that predicts whether a user will download an app after clicking a mobile app ad. To support your modeling, they have provided a generous dataset covering approximately 200 million clicks over 4 days!
Steps of finishing a challenge
There are 4 crucial steps with their importances:
- 80% feature engineering
- 10% making local validation as fast as possible
- 5% hyper parameter tuning
- 5% ensembling
Feature engineering
The most important step for winning a challenge is the feature engineering which can take up 80% importances. For a better prediction, you need add up all features that you can find or compose from your original dataset, such as Group by, unique, count, cumulative_count, sort, shift(next & previous), mean, variance, etc.
Making local validation
The next step is to make a local validation set as fast as possible. Once it is created, you can tune your hyperparameters and test your feature importances on your local validation set.
If you don't have a good validation scheme then you rely solely on LB probing, which can easily lead to overfit.
Hyper parameter tuning
Two most used methods are XGBoost and Light GBM, you can refer to this website xgboost/Light GBM parameters to set up all your parameters quickly.
To get a better accuracy, you need to tune your parameters with Gird Search. For example:
param_grid = {'n_estimators': [300, 500], 'max_features': [10, 12, 14]}
model = grid_search.GridSearchCV(estimator=rfr, param_grid=param_grid, n_jobs=1, cv=10, verbose=20, scoring=RMSE)
model.fit(X_train, y_train)
Ensemble
It is more and more difficult to get good predictions with just a single model. If we can combine several medels, the prediction result could usually be better.
There are some ensemble methods:
- Bagging: Each Base Model is trained using different random subsets of the training data, and the final results are voted by each base model with the same weight. That is the principle of Random Forest.
- Boosting: The Base Model is trained iteratively, each time modifying the weight of the training sample based on the prediction errors in the previous iteration. This is also the principle of Gradient Boosting. Better than Bagging but easier to Overfit.
- Blending: Different Base Models are trained with disjoint data and their outputs are averaged (weighted). Simple implementation, but less use of training data.
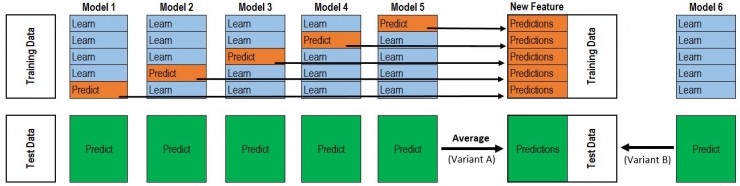
- Stacking: The whole process is very much like Cross Validation. First, the training data is divided into 5 parts, followed by a total of 5 iterations. At each iteration, 4 data are trained as Training Sets for each Base Model, and then the remaining Hold-out Set is used for prediction. At the same time, its predictions on test data should also be preserved. In this way, each Base Model will make a prediction of one of the training data at each iteration and make a prediction of all the test data. After 5 iterations have been completed, we have obtained a matrix of # training data rows x #Base Model number. This matrix is then used as the training data of the second-level Model. After the second-level Model is trained, the previously saved Base Model predicts the test data (because each Base Model has been trained five times, and the entire test data has been predicted five times, so for these five requests An average value, which results in a matrix with the same shape as the second-level training data) is taken out for prediction and the final output is obtained.
Conclusion
Kaggle is possibly the best platform for data scientists to practice their skills. To start with this challenge, I got inspired from kernels and discussions. Then I tried Light GBM and XGBoost that I had never used before. I'll continue fighting on Kaggle!